Efficient Action Spotting Based on a Spacetime Oriented Structure Representation
Contributors
- Konstantinos G. Derpanis
- Mikhail Sizintsev
- Kevin Cannons
- Richard P. Wildes
 |
 |
 |
| Action template: Spin Left |
Action template: Jump Right |
Action template: Squat |
|
 |
| Search results for an aerobics routine with multiple actions |
Overview
This work addresses the problem of action spotting, the spatiotemporal detection and localization of human actions in a video stream. The term "action" refers to a simple dynamic pattern executed by an actor over a short duration of time (e.g., walking and hand waving). Potential applications of the proposed approach include video indexing and browsing, surveillance, visually-guided interfaces and tracking initialization.
Challenges
- Same action yields widely different image intensity patterns.
- Handling geometric (e.g., scale) and temporal (e.g., speed) deformations.
- Performance nuances (i.e., no two instances of the same action are performed exactly the same).
- The appearance of multiple actions in field-of-view.
- Actions containing rapid dynamics.
- Presence of distracting background and foreground clutter.
- Background clutter arises when actions are depicted in front of complicated, possibly dynamic backdrops.
- Foreground clutter arises when actions are depicted with distractions superimposed, as with dynamic lighting, pseudo-transparency (e.g., walking behind a chain-linked fence), temporal aliasing and weather-related effects (e.g., rain and snow).
- Computation efficiency.
Approach
Key to addressing the above challenges is the choice of representation. In our work, local spatiotemporal orientation is of fundamental descriptive power, as it captures the first-order correlation structure of the data irrespective of its origin, even while distinguishing a wide range of image dynamics (e.g., single motion, multiple superimposed motions and temporal flicker). Correspondingly, each point in the query and search videos will be represented according to its local 3D, (x, y, t), orientation structure. In particular, each point of spacetime is associated with a distribution of measurements that indicates the relative presence of a particular set of spatiotemporal orientations. Importantly, the representation is invariant to purely spatial pattern and supports fine delineations of spacetime structure, which makes it possible to tease out action information from clutter. Further, the representation is recovered efficiently via application of a bank of 3D, steerable, separable oriented filters [Derpanis and Gryn, 2005].
To detect an action (as defined by a small template video) in a larger video, the search video is scanned over all spacetime positions by sliding a 3D template over every spacetime position. The pointwise similarity between the template and search volume spacetime orientation distributions (histograms) are computed and subsequently aggregated over the template extents. Peaks in the similarity volume (above a threshold) correspond to the presence of the desired action. Efficient exhaustive search is realized by recasting the search problem in the frequency domain.
The overall approach to action spotting is illustrated in the figure below.
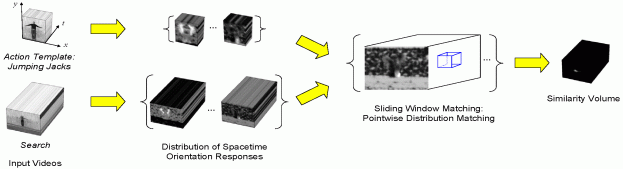 |
| Overview of approach to action spotting. (left) A template and search video serve as input; both these videos depict the action of "jumping jacks". (middle-left) Application of spacetime oriented energy filters decomposes the input videos into a distributed representation according to 3D, (x, y, t), spatiotemporal orientation. (middle-right) In a sliding window manner, the distribution of oriented energies of the template is compared to the search distribution at corresponding positions to yield a similarity volume. (right) Finally, significant local maxima in the similarity volume are identified. |
Results
The performance of the proposed action spotting approach has been evaluated on an illustrative set of test sequences; for video results see supplemental video. In addition, for the purpose of quantitatively evaluating the approach, action spotting performance was tested on the publicly available CMU action data set. In general, the proposed approach achieves significantly superior performance over the state-of-the-art.
Supplemental Material
Related Publications
- K.G. Derpanis, M. Sizintsev, K. Cannons, and R.P. Wildes, Action Spotting and Recognition based on a Spacetime Oriented Structure Representation, IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI) 35, 2013.
- K.G. Derpanis, M. Sizintsev, K. Cannons, and R.P. Wildes, Efficient Action Spotting based on a Spacetime Oriented Structure Representation, In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition (CVPR), 2010.
- K.G. Derpanis and J.M. Gryn, Three-Dimensional nth Derivative of Gaussian Separable Steerable Filters, International Conference on Image Processing (ICIP), 2005, vol III, pp553-556.
Last updated: February 4, 2013
|


