Dynamically Encoded Actions based on Spacetime Saliency
Contributors
- Christoph Feichtenhofer (TU Graz)
- Axel Pinz (TU Graz)
- Richard P. Wildes
Overview
Human actions typically occur over a well localized extent in both space and time. Similarly, as typically captured in video, human actions have
small spatiotemporal support in image space. This project capitalizes on these observations by weighting feature descriptors for action recognition
over those areas within a video where actions are most likely to occur. To enable this selective pooling operation, we define a novel measure of space-time saliency that is designed to highlight human actions in temporal sequences of images. Figure 1 illustrates our approach for a ball catching
action and compares our spacetime saliency measure with ground truth annotations from [4] and [10].

Approach
We approach action recognition within the popular Bags-of-visual-Word (BoW) framework, consisting of three general steps: primitive feature
extraction, feature encoding and feature pooling that accumulates encoded features over pre-defined regions. The major novelty in our contribution
arises via selective encoding and pooling. Our approach dynamically encodes and pools primitive feature measurements via a new definition of
spacetime saliency weights. While previous research has made use of saliency measures as part of an action recognition approach (e.g., [2, 8]),
ours is novel in its definition of spacetime saliency based on directional motion energy contrast and spatial variance to capture actions. These two
components are motivated directly by two corresponding observations about foreground human actions. First, actions typically involve a foreground motion that is distinct from the surrounding background. Indeed, even in the presence of global camera motion, a foreground action will exhibit a different (superimposed) pattern of motion. For example, a participant in a sporting event will yield a motion that is distinct from that of overall camera motion when he or she is engaged in their sporting activity. We refer to this property as motion contrast. Second, action patterns typically are spatially compact, while background motions are more widely distributed across an image sequence. For example, even interactions between two people (e.g., a hug, handshake or kiss) occupy a relatively small portion of an image. We refer to this second property as motion variance. In combination, these two properties are used to define our measure of spacetime saliency for capturing foreground action motion.
In general, our dynamically adaptive salience weighting can be applied essentially to any local feature measurements in support of action recognition. Here, we illustrate it using various combinations of Improved Dense Trajectories (IDT) [9] and a novel extension to Spatiotemporal Oriented Energies (SOE) [3], termed Locally Aggregated Temporal Energies (LATE), both encoded by Fisher vectors [6].
Results
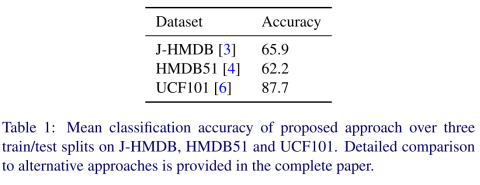
The overall saliency weighted approach to action recognition has been evaluated on three standard datasets: J-HMDB [4], HMDB51 [5] and UCF101 [7]. Table 1 provides a sampling of our empirical results, with detailed comparison to alternatives available in the complete paper. It is found that the appoach yields results that are competitive with and can even exceed the previous state-of-the-art. These results suggest the importance of explicitly concentrating processing on regions where an action is likely to occur during recognition.
Following are a selection of videos from the J-HMDB [4] dataset as well as their salience maps as computed by our approach (brighter intensities correspond to greater salience). Notice how the approach consistently highlights those portions of the videos where human actions occur. There also is tendency to highlight untextured regions that are adjacent to textured ones (e.g., the sky in the golfing example), as its underconstrained structure contrasts with the non-moving (zero velocity) of the region below.
Related code and Information
Please contact the [author]
Related Publications
- [1] Christoph Feichtenhofer, Axel Pinz and Richard P. Wildes, Dynamically encoded actions based on spacetime saliency. In Proc. CVPR 2015.
- [2] Nicolas Ballas, Yi Yang, Zhen-Zhong Lan, Bertrand Delezoide, Fran-
coise Preteux, and Alexander Hauptmann. Space-time robust represen tation for action recognition. In Proc. ICCV, 2013.
- [3] Konstantinos G. Derpanis, Mikhail Sizintsev, Kevin J. Cannons, and
Richard P. Wildes. Action spotting and recognition based on a spatiotemporal orientation analysis. PAMI, 35(3):527–540, 2013.
- [4] Hueihan Jhuang, Juergen Gall, Silvia Zuffi, Cordelia Schmid, and
Michael J. Black. Towards understanding action recognition. In Proc.
ICCV, 2013.
- [5] Hildegard Kuehne, Hueihan Jhuang, Estíbaliz Garrote, Tomaso Poggio,
and Thomas Serre. HMDB: a large video database for human motion
recognition. In Proc. ICCV, 2011.
- [6] Florent Perronnin, Jorge Sánchez, and Thomas Mensink. Improving the
Fisher kernel for large-scale image classification. In Proc. ECCV, 2010.
- [7] Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. UCF101:
A dataset of 101 human actions calsses from videos in the wild. Technical Report CRCV-TR-12-01, UCF Center for Research in Computer
Vision, 2012.
- [8] Waqas Sultani and Imran Saleemi. Human action recognition across
datasets by foreground-weighted histogram decomposition. In Proc.
CVPR, 2014.
- [9] Heng Wang and Cordelia Schmid. Action recognition with improved
trajectories. In Proc. ICCV, 2013.
- [10] Silvia Zuffi and Michael J Black. Puppet fow. Technical Report TRIS-
MPI-007, MPI for Intelligent Systems, 2013.
|


